

Share Post
Automated Optical Character Recognition (OCR), Intelligent Character Recognition (ICR) and Natural Language Processing (NLP) software can turn your company’s document dystopia into a data-rich paradise. We are here to answer your remaining questions about OCR, ICR and NLP, and to show you how these technologies can benefit your operations.
What is OCR / ICR and how do they work?
OCR stands for "Optical Character Recognition." This technology—commonly used to recognize text in scanned documents and images—converts a physical or digital document into an accessible electronic version with searchable text.
The best OCR solution can take almost any form of document—be it a photo of a text or a scanned TIFF, Excel, PDF, Word, or PowerPoint file— and convert it into a full-text, searchable PDF complete with metadata that is a one-to-one representation of the original document.

In the example above, the original document was a scanned image of an agreement, and not searchable. Optical Character Recognition turned this file into a text-searchable document that can be saved as a full-text PDF with all file attributes, such as selection and copying of content, in-document search, text highlight, etc.
With time, OCR has evolved into intelligent character recognition (ICR) technology, which is capable of recognizing handwritten text and/or fonts. In comparison, OCR specializes in capturing typed-up content. Since ICR can process handwriting and complex fonts, it can manage more document types than OCR alone.
Further, under the OCR umbrella, live the lesser-known optical recognition siblings, such as optical mark recognition (OMR), magnetic ink character recognition (MICR), and 1D and 2D barcode recognition (BCR).
- OMR is primarily used to recognize answer patterns and automatically evaluate bubble optical answer sheets used in multiple choice exams across the United States and most of EU.
- MICR is mainly used in the banking industry to scan, read and capture magnetic characters on the bottom of cheques and other vouchers, thus streamlining processing of cheques and similar documents.
- Barcode readers, or sometimes BCRs, unlike traditional laser devices used to scan a barcode from a physical object, “read” the barcode from a digital image and/or file. Adding barcodes to documents with irregular formatting ensures that document metadata is read in a matter of seconds and with 100% accuracy.
What is NLP and how is it connected to OCR?
NLP stands for natural language processing and is a Machine Learning (ML) science focused on teaching computers to understand speech patterns, contextual and language nuances. NLP is the main technology used for classification and analyzing of documents, and subsequently extraction of data.
Optical Character Recognition (OCR) and Natural Language Processing (NLP) are often used together to provide high-accuracy document digitization and classification. OCR is used to scan, recognize text in various file formats like images, emails, PowerPoint presentations, scanned receipts, and more, and convert them into digital text documents, like PDF, XML, and other, for further processing in Enterprise Content Management (ECM) systems. NLP is then used to contextualize the content and classify the documents to provide better insight for data analysis, such as adding search filters for document filing, extracting metadata and more.
What is the difference between Free OCR and Enterprise-grade OCR?
OCR technology has been around for decades, and the internet is proliferated with countless OCR and NLP solutions, price range from freeware to thousands of dollars.
What sets a freeware OCR solutions apart from an enterprise-grade Document Transformation platform? When looking for an enterprise OCR solution, consider the following:
- Ability to process hundreds of file formats
Many tools today offer free OCR services for every day uses. For example, Microsoft OneNote or Photo Scan apps, Google Docs, SimpleOCR or even most mobile camera apps can lift the text from an imported image. These are generally limited to working with the popular image files, such as jpeg, png, tiff and bmp. The accuracy of the end result is dependent on the quality and resolution of the image and ranges anywhere from 80% - 90%. (More on OCR quality later.) If your business works with documents that originate from different sources and come in a range of file types, consider looking into a robust solution that can ingest and output various file formats.

- Offers the OMR, BCR and ICR capabilities
Businesses in highly-regulated sectors, such as bio-pharmaceuticals, banking, insurance, legal and energy, should consider an OCR solution that is capable of capturing, digitizing and classifying complex content elements, such as forms, barcodes, e-signatures, stamps, handprints, etc. In these industries, poorly scanned and transcribed documents may result in fines associated with non-compliance with multiple government mandates, lost revenue due to product launch delays, and degradation of customer service due to irregular and/or poor client data. - OCR quality
When the integrity of data captured from the unstructured content is critical for business operations, OCR accuracy plays a huge role in ensuring excellent customer service, risk management and accurate business insights. When it comes to OCR accuracy, 98-99% is considered high, while below 90% is poor. Even still, with 99% accuracy, in a document with 1000 transcribed characters, 10 may result in errors. A best of breed OCR solution enriched with artificial intelligence and machine learning will generally rely on ICR and NLP along with human verification factor to mitigate those errors. Be sure to look for an OCR solution that will not put you in hot water over 1 mistranscribed character. - Capability to process multi-page documents and multi-document jobs
With most free OCR solutions, users can process one image at a time. When you have 10 or so images, it is a non-issue. When your business processes hundreds or thousands of documents per day, your chosen OCR solution must operate in a job-based structure and be robust enough to take on small to large files with millions of characters. - Converts files using the original application
fc11.gif)
Imagine you have to OCR a legacy Corel Draw file and convert it to PDF. Your organization no longer carries the Corel Draw license and without it your team members are unable to access the original blueprints resulting in project delays. Or your organization has upgraded internal billing system and lost access to millions of customer records created by the previous software. Scenarios like these may cause a minor frustration, or a major customer service crisis, or worse - lost business. The right solution will use native application rendering to replicate the source document with near-identical accuracy, ensuring the PDF output retains the integrity of the original imagery, branding and formatting.
Check out our list of 10 key capabilities of an enterprise-grade Advanced Document Rendering solution > - Auto language detection and preloaded global language library
The benefit of a multi-lingual OCR solution is that it can perform auto word corrections. An enterprise-grade OCR solution will be able to process majority of global languages, and even have the capability to recognize and auto-correct contextual industry-specific terminology. Even more, higher-end solutions will allow users to upload their own taxonomy in many different languages to use for auto-correction. When your business is global and operates in many different countries, multi-lingual OCR is non-negotiable for the integrity of your content around the globe. - Integrated solution with RPA and workflow framework
When it comes to digitizing thousands of documents, workflow automation and integration with existing business systems will be key in streamlining this process. After all, document conversion doesn’t happen in a vacuum. The right solution for your company will need to be designed in such a way that allows for easy connection to your ECM, take the content from there, process it and output clean, digital structured files back into the system with minimal human intervention.
Why do your operations need OCR?
Enterprise Content Management (ECM) systems provide 3 vital functions in many organizations: helping you integrate your processes, improve information access, and ensure governance through a central content management platform. While this technology is a step up from the stuffing-paper-into-filing-cabinets phase, ECM systems are not without issue.
According to Forrester, 70% of enterprises use 2 - 4 Enterprise Content Management (ECM) systems, while 29% use 4 or more. Content duplication and version control across multi-ECM ecosystem is a painful reality that IT and content management teams work tirelessly on resolving.
Employee and customer generated documents, such as SOPs, emails, presentations, etc., represent 80% of company’s data, and are completely ‘dark’. Forbes reports that 95% of businesses cite the need to manage their unstructured data as a business problem.
“For the majority of workers, it can take hours or even days to find the right data they need. Only 3% of employees can get the data to answer their questions in seconds.”
— Sigma: Top 20 Big Data Statistics for 2020
Highly-regulated industries, such as oil and gas, insurance, and bio-pharma, are plagued by the immense amounts of documentation required to run a compliant, competitive, and profitable organization. These documents, which can number into the millions, typically come in a dizzying array of formats and represent a significant portion (~80%!) of enterprise content. The challenge is that even though majority of these are digital, they are completely unsearchable, rendering their content useless to other applications and analytics software.
The first step toward digitization is ensuring that content is in a machine-readable format that can be easily accessed and processed.
This is where OCR comes to the rescue. An enterprise OCR solution is capable to take all that dark, unstructured, unsearchable content and transform it into digital, indexable format complete with metadata that feeds into your ECM systems. Read this blog to learn why metadata is important >
A good enterprise OCR platform not only delivers critical business insight into your boardrooms, it also de-duplicates your company content, prepares it for long-term archiving according to government mandates, and significantly improves internal information sharing.
If you are still unsure about the benefits of an enterprise OCR solution, ask yourself these questions:Data-driven organizations are 23 times more likely to acquire customers than their peers.
— McKinsey Global Institute
- Will it make your co-workers more efficient if they could easily navigate and find all relevant information contained in company documents?
- Would it improve your relationship with customers if your frontline staff could pull up all customer relevant data in a matter of minutes while speaking with them on the phone?
- Would your leadership consider it critical to gain insight into company data hidden across email threads, attachments, presentations and other documents?
- How much time would it save your senior team members to onboard new employees and share knowledge with increased transparency into company documentation?
- Would your business analysts gain a higher confidence level when human data entry errors have been eliminated with automated data capture?
- Would your teams become more efficient if they could focus on business-critical tasks versus spending time on manually searching, transcribing, fixing, converting files to digital PDFs?
What is so special about Adlib’s OCR and NLP?
There are many desktop OCR applications on the market today but very few server-based ones. Taking advantage of the benefits offered through server technologies, Adlib’s OCR offers superior performance and accuracy. Check out how Adlib can scale CPU utilization and take on processing hundreds of thousands of pages for our enterprise customers.
Adlib is a leading enterprise solution with a high customer satisfaction rate: 95% of leading pharma companies use and trust Adlib.
- Helen Rosen, CEO of Adlib
Here are the 10 ways Adlib OCR is a superior product on the market:
- Supports 300+ file formats
Adlib can OCR and convert to PDF over 300 file extensions using native applications preserving original document’s formatting. - Recognizes 115 languages
Automatically detects languages with built-in dictionaries to ensure highest possible accuracy for global content. - Speed/Accuracy Optimization
Users can toggle OCR settings to optimize the balance between speed and accuracy suitable for their needs. - 99% accuracy levels
De-skew and de-speckle page clean-up settings increase character recognition accuracy, while intelligent character recognition and natural language algorithms detect and auto-correct errors. - Complex content element recognition
Capabilities to process OMR, Zonal OCR, 1D and 2D BCR make Adlib a complete enterprise-grade OCR solution
- Document fidelity
Adlib’s OCR creates a fully-digital text layer on top of your document maintaining its original formatting, branding and imagery.
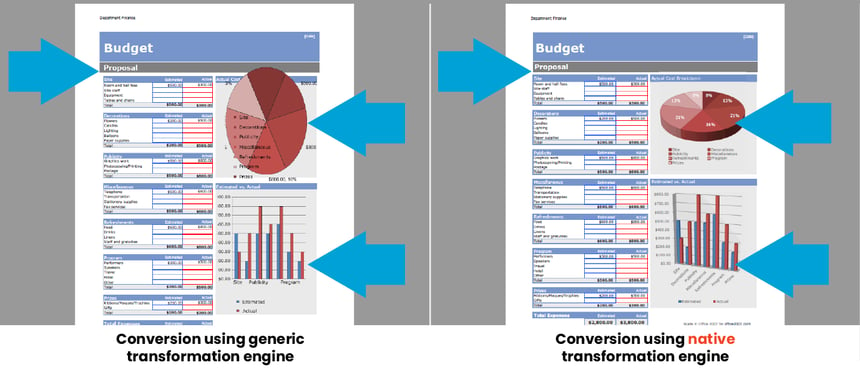
- Word Corrections
Adlib OCR performs auto-corrections in 17 global languages. Leveraging pre-loaded industry dictionaries, Adlib provides word corrections for Financial, Legal and Medical terminology in 4 languages. In addition, Adlib OCR has the option to auto-correct words used in your organization utilizing user-created dictionaries. - Compression and archiving features
Designed specifically for enterprises, Adlib solution supports JBIG2 and MCR file compression to generate smallest possible file size and has the option to output archive-compliant PDF/A format in line with archiving regulatory bodies, such as NARA. - Load balancing and large file processing
Adlib is a high-performance solution that supports load balancing with high availability and advanced error handling to process multiple jobs of multi-page documents and large file sizes. - Connection to existing ECM
Adlib seamlessly integrates with all leading ECM solutions, such as OpenText, FileNet, Dropbox, Dassault Enovia, Nintex, K2, and can connect to virtually any business application via the Web API framework.
Digital Transformation cannot succeed without a robust OCR platform
To set up your organization for a successful digital transformation, choosing the right OCR solution for managing your unstructured data is critical for ensuring data confidence, seamless automation and reliable output.
Book a demo with one of our experts.


